(待续)
天池竞赛城市计算AI挑战赛以“杭州市地铁乘客流量预测”为题,提供了杭州市2019年1月1日到25日的地铁刷卡流量数据,要求预测出未来时间的客流变化情况
赛题简介
赛题提供了以下文件
- Metro_train.zip,包含25天的刷卡数据,每天为一个单独的.csv文件
- testA_record_2019-01-28.csv,测试集,用来测试模型性能
- Metro_roadMap.csv,各地铁站点连接关系
刷卡数据格式为
| 列名 | 类型 | 说明 | 示例 |
|---|---|---|---|
| time | String | 刷卡发生时间 | 2019-01-02 00:30:53 |
| lineID | String | 地铁线路ID | C |
| stationID | int | 地铁站ID | 15 |
| deviceID | int | 刷卡设备ID | 2992 |
| status | int | 进出站状态,0表示出站,1表示进站 | 1 |
| userID | String | 用户ID | C21b87e232a083b3e7d6d45e2ff933e31 |
| payType | int | 刷卡类型 | 0 |
Metro_roadMap.csv文件中是一个2维矩阵,首行和首列是地铁站ID,roadMap[i][j]为1表示stationID为i的地铁站和为j的地铁站相连,为0表示不相连
数据分析
初步分析
使用pandas对数据做一个初步分析
整体情况
首先读取一个数据文件,查看结构
1 | data = pd.read_csv(path+'/record_2019-01-01.csv') |
可以看到,文件结构与描述一致,从左到右,列依次为time、lineID、stationID、deviceID、status、userID和payType
1 | data.info() |
除了首行,数据共2539592条,占用106MB内存
查看描述信息
1 | data.describe() |
由描述信息可看出
- 共有253万次刷卡数据
- 地铁站ID从0到80,共81条地铁线
- 刷卡设备ID从0到3638,共3639个刷卡设备
- payType从0到3,共4种刷卡方式
基本统计
查看地铁线路统计信息
1 | data.lineID.nunique() |
共3条地铁线,分别为A、B、C,其中地铁线路B流量最大为167万,C次之为64万,A最小为21万
查看地铁站统计信息
1 | data.stationID.value_counts() |
站点15的流量最大,站点9次之
用户统计分析
1 | user_counts = data.userID.value_counts() |
由用户统计分析可看出
- 总的地铁出行用户数为91万人
- 只有4.6万人刷卡次数超过5次,1万人刷卡次数超过10次,60万人刷卡次数为2,24万人刷卡次数为4次
挖掘规律
由以上基本分析可得出几个关键结论
- 从地铁线路来看,流量大小依次为B>C>A
- 从地铁站来看,15站点流量极高,9站点次之
- 从用户信息来看,大量用户刷卡次数在5次以下,其中66%的用户是单程
由以上结论,提出以下问题
- 为什么B线流量大?
- 为什么15站和9站流量大?
- 为什么单程用户流量大?单程的起始和终点集中在哪些线路和站点?往返用户占多少?
为什么B线流量大?
猜测B线流量大,可能是因为B线站点数量多,B线存在交通枢纽站点,或者B线上某些站点周边覆盖人口密度大
查看各线路站点数
1 | data[data.lineID=='A'].stationID.nunique() |
可看到B线站点数量为34最多,C线32站,A线最少,只有14站
查看各地铁线站点流量情况
1 | data[data.lineID=='A'].stationID.value_counts().describe() |
可看到地铁线A最大站点流量才2.9万,平均在1.5万;B线最大站点流量为35万,平均为4.9万;C线最大流量站点为3万,平均为2万;因此,B线大部分站点流量都较高,例如15站、9站等高流量站点,都属于B线,所以导致B线整体流量较大
为什么15站和9站流量大?
仅仅从训练数据种,无法得出15站和9站的其他信息,站点流量大小很大程度上取决于其周边设施以及本站是否为换乘站
根据赛题给出的站点连接关系,总结出以下交汇点
| 站点1 | 站点2 |
|---|---|
| 28 | 20 |
| 51 | 9 |
| 50 | 10 |
| 51 | 10 |
| 52 | 10 |
| 74 | 5 |
| 75 | 5 |
| 80 | 15 |
| 77 | 46 |
| 78 | 46 |
根据站点交汇关系,以及各地铁线路的总站点数,再结合杭州市地铁图,可确定
- B线为1号线、C线为2号线,A线为4号线
- B线站点范围为0~33,其中0为湘湖,5为近江,10为凤起路,15为火车站,20为客运中心,27为下沙滨江,33为临平
- C线站点范围为34~66(54不存在),其中34为朝阳,46为钱江路,51为凤起路
- A线站点范围为67~80,74为甬江路,75为城星路,77为江锦路,78为景芳
15站为火车站,由于刷卡数据为2019年1月份,临近春节,因此猜测15站流量大是因为春运流量
9站为龙翔桥,经百度地图查看,该站点临近西湖,且周边为商业繁华地带,而读取的数据文件是1月1日元旦,因此流量大
为什么单程用户流量大?
查看单车用户集中在哪些站点
1 | user_counts = data.userID.value_counts() |
单程用户613793人,那么总流量为613793*2=1227586次。单程流量集中在15、9、7、20、11、24、25,15为火车站,9为龙翔桥,7为客运站,20为客运中心,11为商圈和住宅中心,24、25是大学城,因此可判断单程流量主要是由于临近春运的各大车站出入人口,以及元旦假期的出入人口
可视化
编写代码,以天为单位,绘制总流量图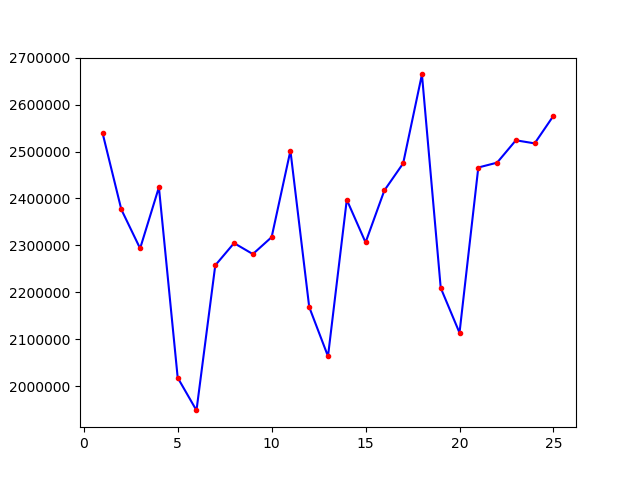
由上图可看出,总流量以周为单位,呈周期性变化,规律是周内工作日流量较高,周5到达峰值,周末降到峰谷(除了1月1日的元旦假期)
总的趋势是无论周内周日,随着时间临近春节,整体流量有上升趋势
以时刻为单位,绘制3条地铁线的某天实时流量图,发现所有周内情况与下图类似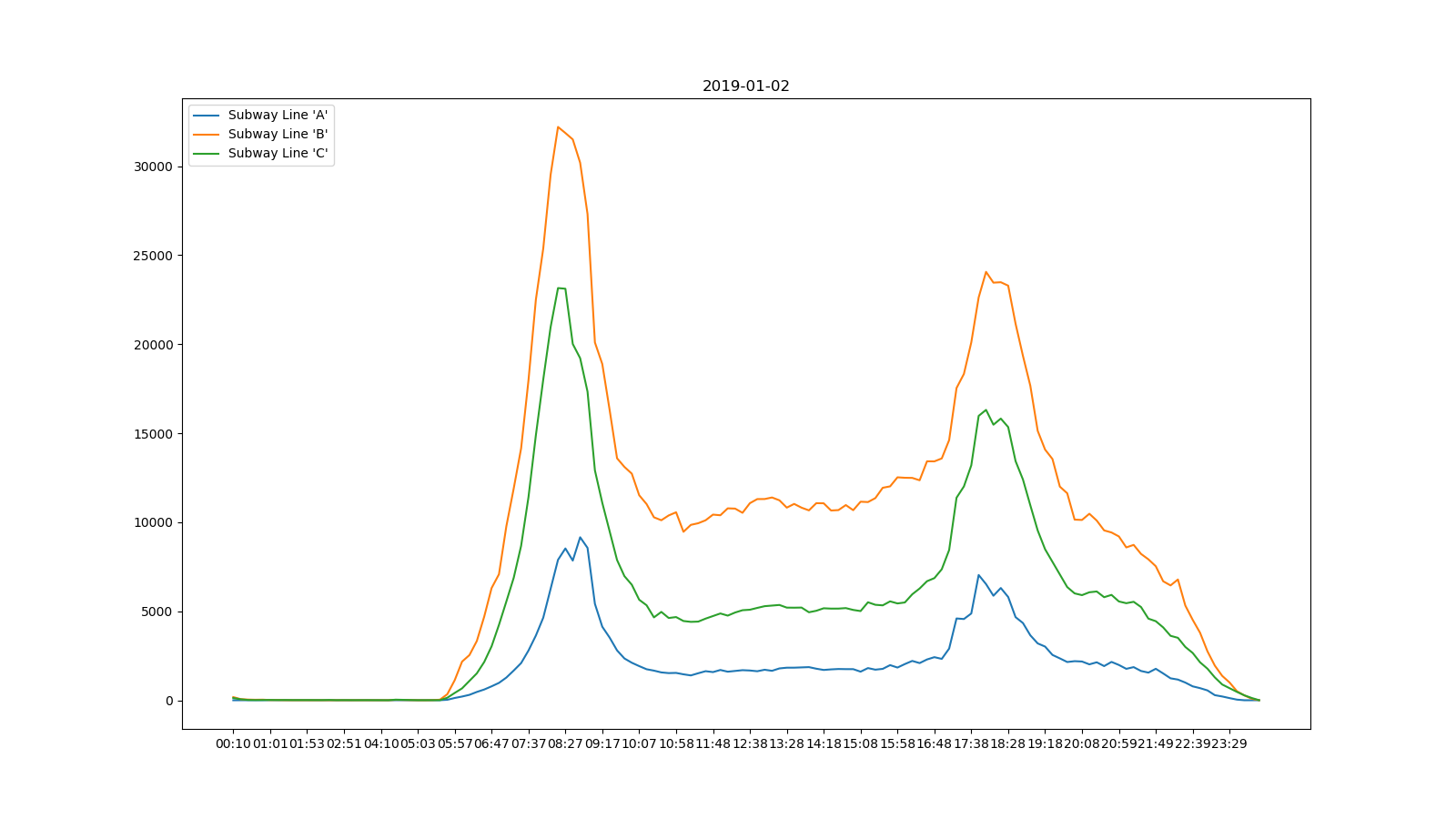
整天的流量呈现双峰现象,分别集中在早8点和晚6点,是上下班流量
周末的流量与下图类似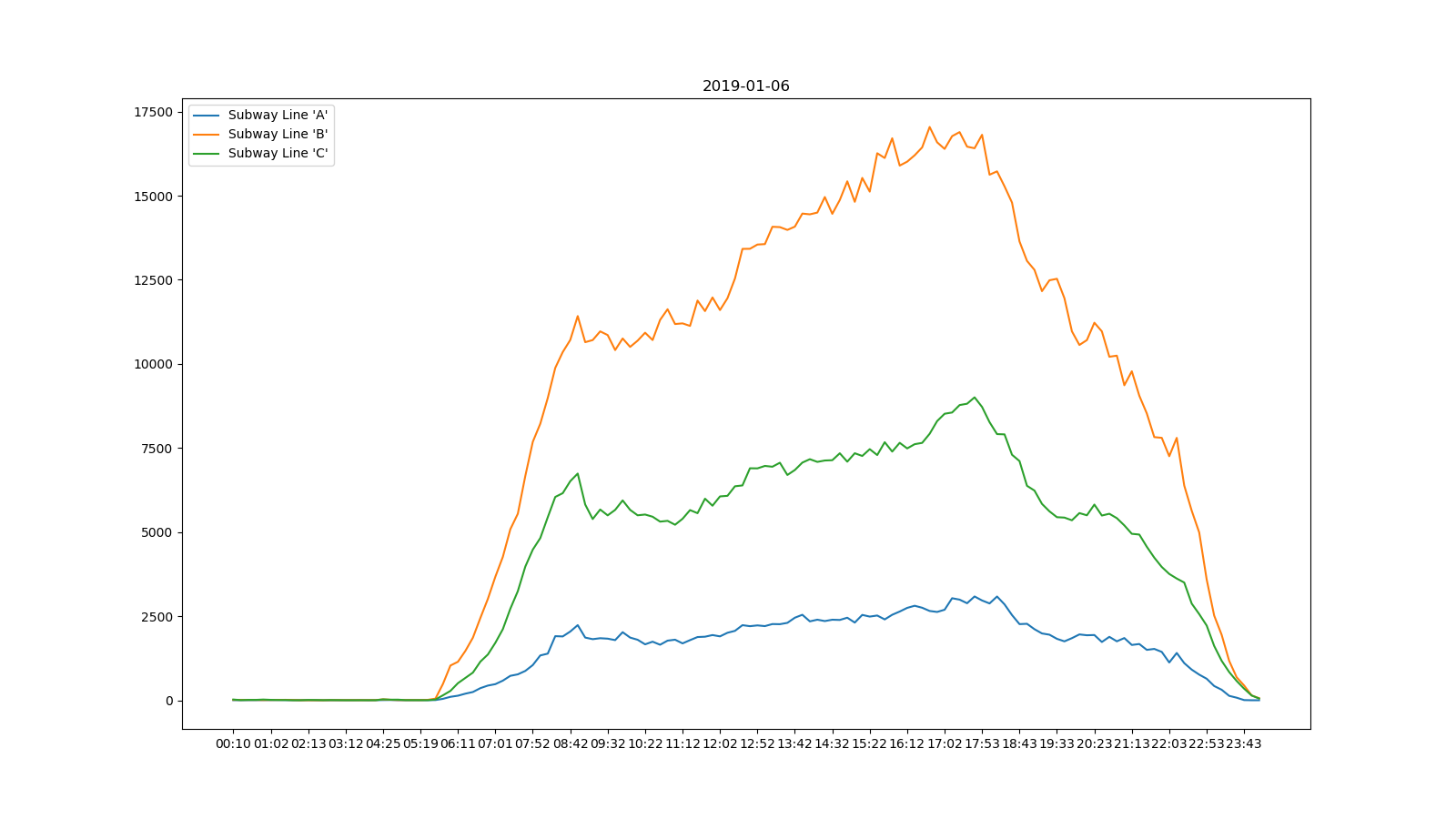
1月1日元旦的流量图如下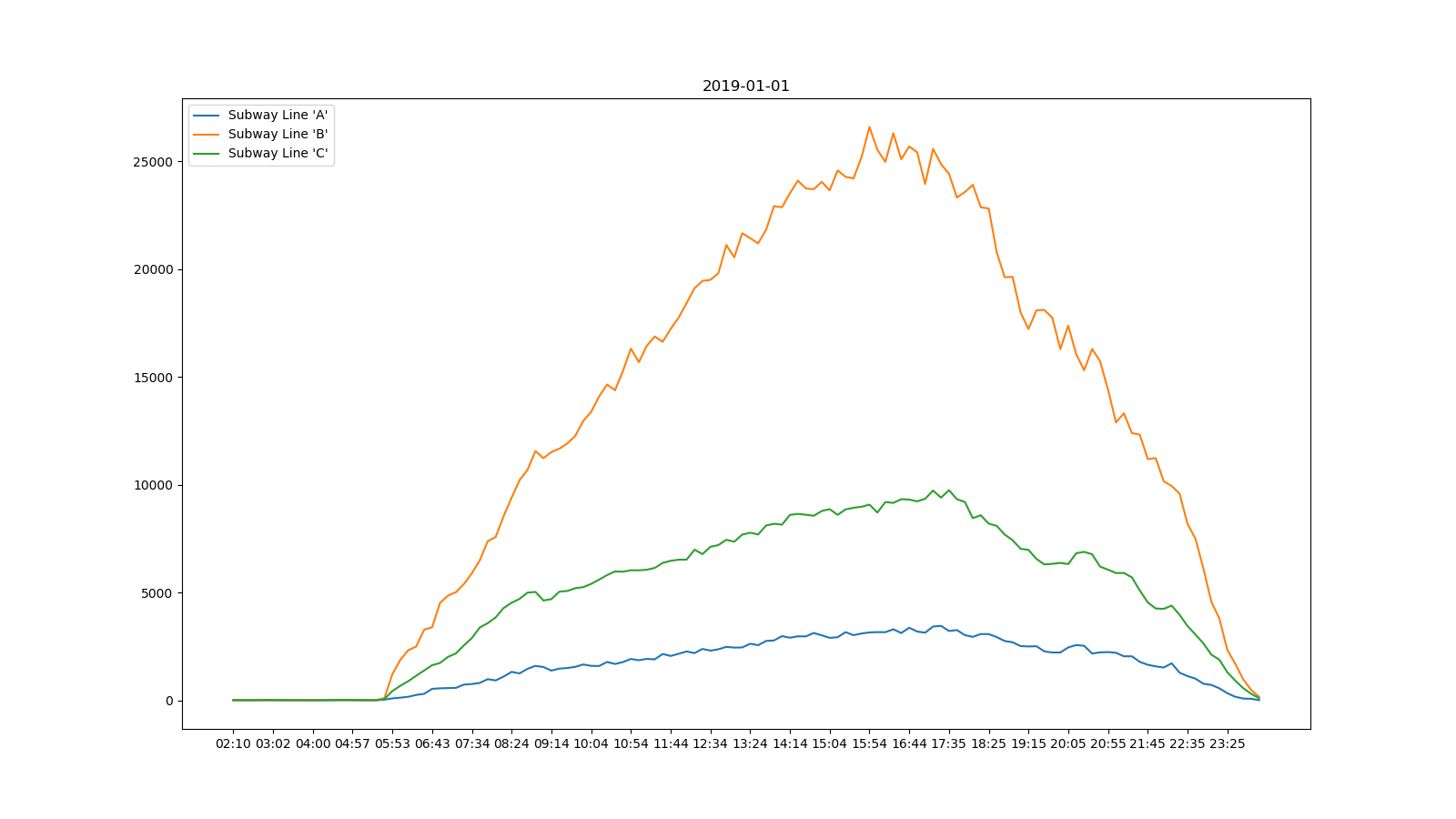
周内分析
查看数据摘要
1 | data = pd.read_csv(path+'record_2019-01-02.csv') |
可看到1月2日总流量为2376462
1 | user_counts = data.userID.value_counts() |
总刷卡人数为74万,刷卡数主要集中在单程和往返
查看单程车站分布
1 | user_counts = data.userID.value_counts() |
可以看到,单程流量较高的车站有
- 15:杭州东站
- 7:城站
- 9:龙翔桥
- 4:江陵路
- 20:客运中心
- 11:武林广场
- 33:临平
15、7和20客流量大是因为虽然是周内,依然是春运高峰期,或者元旦假期结尾的返程客流;9龙翔桥站靠近西湖景区,且周边有很多商业热点,猜测可能是经常性大流量;其余站点流量大还需要分析原因
查看杭州东站的人流方向
首先查看从杭州东站进的人主要去往哪些站点
1 | s15_in_users = data[data.stationID==15][data.status==1].userID.values |
可看到,从15站进入的人,主要去往了11、24、25、7、9这几个站点,24、25是大学城区域,猜测是元旦假期返程人流;7是靠近杭州火车站,猜测是从东站换乘的春运人流;9站更加可以说明是从火车站来西湖游玩的日常流量;7站比9站里西湖稍远,但是也属于靠近西湖的站点,且周边住宅、商业热点众多,因此猜测也是和到西湖游玩有关
查看去往杭州东站的人主要来自哪些站点
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s15_out_users)) & (data.stationID!=15)].stationID.value_counts()[0:5] |
可看到,从15站出站乘坐高铁的人,主要来自9、7、11、20、33几个站点
- 9:西湖游玩返程的人
- 7:春运换乘上高铁
- 11:西湖游玩返程的人
- 20:春运换乘上高铁
- 33:此站点远离市区,猜测可能房价偏低,人口密度大,也是属于春运客流
查看城站的人流方向
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s7_in_users)) & (data.stationID!=7)].stationID.value_counts()[0:5] |
可看到从城站进地铁的人流主要去往了15和4站点,15站是因为春运换乘,4站点是因为居住区
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s7_out_users)) & (data.stationID!=7)].stationID.value_counts()[0:5] |
可看到去往城站的人流,主要来自15站,因为春运换乘
查看龙翔桥的人流方向
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s9_in_users)) & (data.stationID!=9)].stationID.value_counts()[0:5] |
从龙翔桥出发的人流主要去往了15站,是从西湖游玩返程的
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s9_out_users)) & (data.stationID!=9)].stationID.value_counts()[0:5] |
去往龙翔桥的人流主要来自15站,是去西湖游玩的
查看江陵路人流方向
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s4_in_users)) & (data.stationID!=4)].stationID.value_counts()[0:5] |
江陵路人流主要去往15和7站点,是春运出发
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s4_out_users)) & (data.stationID!=4)].stationID.value_counts()[0:5] |
江陵路人流主要来自15和7站点,是春运返程
查看客运中心人流方向
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s20_in_users)) & (data.stationID!=20)].stationID.value_counts()[0:5] |
客运中心人流主要去往15站点,春运
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s20_out_users)) & (data.stationID!=20)].stationID.value_counts()[0:5] |
客运中心人流主要来自15站点,春运
查看武林广场人流方向
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s11_in_users)) & (data.stationID!=11)].stationID.value_counts()[0:5] |
武林广场人流主要来自15站点,春运和去西湖游玩
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s11_out_users)) & (data.stationID!=11)].stationID.value_counts()[0:5] |
武林广场人流主要去往15、7站点,春运和西湖游玩返程
查看临平人流方向
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s33_in_users)) & (data.stationID!=33)].stationID.value_counts()[0:5] |
临平人流主要来自15站点,春运
1 | data[(data.userID.isin(oneway_users)) & (data.userID.isin(s33_out_users)) & (data.stationID!=33)].stationID.value_counts()[0:5] |
临平人流主要去往15站点,春运
查看返程车站分布
1 | data[data.userID.isin(twiceway_users)].stationID.value_counts()[0:10] |
返程站点流量前10位为4、15、9、12、7、16、10、11、22、5,查看这些站点附近热点
- 4,市公安局、滨江区政府、武警医院、江锦汽车有限公司、中财、中化、海康威视、吉利集团、百得利
- 9,市第一人民医院、浙大附属产科医院、银泰、天长小学、思鑫坊、胜利剧院、国贸中心、浙江省中医院、惠星中学
- 12,环球中心、科技馆、清园小区、通盛嘉苑、武林府、中山北园、西子花园、河东社区
- 7,建国中路小区、长明寺巷社区、第二中学、葵巷社区、新东方、浙大附属第一医院、银联、国贸、国税局、中闽大厦、国家电网、第六中学、三益里小区、第三人民医院
- 16,宇威德信、三花国际、港龙城、新和嘉苑、德信东望、明月嘉苑、明月嘉苑、夏衍小学
- 10,换乘站、皇亲苑社区、皇后公园、第十四中学、长寿社区、锦绣天地、杭州嘉里中心、建德路小区、凤麟社区、镜瑞弄、国都公寓、麒麟公寓、儿童医院、竹竿巷社区
- 11,国大城市广场、杭州百货大楼、浙信大厦、国信大厦、元通大厦、广发大厦、下城区人民医院、南都天水苑、仓桥社区、天水阳光家园、长江实验小学、天巢花苑、杭州大厦购物城、文化会堂浙江展览馆、浙江展览馆南广场、武林广场、电信大楼、中国电信、天水小学
- 22,经济技术开发区、龙湖滟澜山、龙湖时代金沙天街、德信中外公寓、名城湖左岸、新元社区、金沙城、金沙湖、和达御观邸、上沙锦湖家园、金沙湖公园
- 5,换乘站、杭州市公安局、望江公园、杭州市建兰中学分校、近江东园社区、近江家园、天福花园、滨江新苑、崇文实验学校、胜利小学、开元中学、妇产科医院、万泰城、文华苑、林风花园
1 | user_counts = data.userID.value_counts() |
s13_in_users = data[data.stationID==13][data.status==1].userID.values
s13_out_users = data[data.stationID==13][data.status==0].userID.values