梯度下降(GD, Gradient Descent)和反向传播(BP, Back Propagation)是理解神经网络学习原理的核心,本文试图从数学原理、实例来分析梯度下降和反向传播在神经网络中是如何工作的
数学原理
为了理解梯度下降算法和反向传播算法的工作原理,需要理解以下数学知识
- 方向导数和梯度
- 链式法则
方向导数
梯度在数学中的概念,源于方向导数。在一元函数中,我们用导数来描述和分析函数的变化趋势,二元函数或多元函数我们用偏导数来分析函数变化情况。但是一旦变成多元,偏导数只能反应在坐标轴方向的变化情况,如果想要知道函数在任意方向上的变化情况,偏导数是无法做到的。因此引入了方向导数的概念
$l$ 是 $xOy$ 平面上以 $P{0}(x{0},y{0})$ 为起点的一条射线,$e{l}=(\cos{\alpha},\cos{\beta})$ 是与 $l$ 同方向的单位向量,$P$ 为射线上另一点。如果函数 $z = f(x,y)$ 的增量 $f(x{0}+t\cos{\alpha}, y{0}+t\cos{\beta})$ 与 $P$ 到 $P{0}$ 的距离 $\left|PP{0}\right| = t$ 比值
当 $P$ 趋于 $P{0}$ 时的极限存在,则称此极限为函数在点 $P{0}$ 沿着射线 $l$ 的方向导数。简单来说,方向导数就是函数在某一点上(当然这一点必须是在函数上的),沿着某一个方向的变化率,但是方向导数并不是在任何方向上都存在,有定理:
- 如果函数在某一点可微,函数在该点的任何方向的方向导数存在
梯度
函数在很多方向上都有方向导数,那么在哪个方向上变化率最大呢?
如果函数在点 $P{0}$ 可微,$e{l} = (cos\alpha, cos\beta)$ 是与方向 $l$ 同方向的单位向量,则方向导数可以写成如下形式
其中 $\nabla f\left ( x{0},y{0} \right )$ 就是梯度,$\theta$ 是梯度与单位向量的夹角。反过来,可以将方向导数看做梯度在任意方向上的投影,当这个夹角 $\theta$ 为0时,表示方向导数与梯度同方向,函数增长速度最快,当夹角 $\theta$ 为180度时,方向导数与梯度方向相反,函数减小最快
梯度的表达式为
本质上是函数的各个偏导数合成的向量
链式法则
微积分中的链式法则用于计算复合函数的导数。设$x$为实数,$f$和$g$是从实数映射到实数的函数,假设$y=g(x)$且$z=f(g(x))=f(y)$,那么链式法则为
扩展到向量,假设$\boldsymbol{x} \in \mathbb{R}^{m}$,$\boldsymbol{y} \in \mathbb{R}^{n}$,$g$是从$\mathbb{R}^{m}$到$\mathbb{R}^{n}$的映射,$f$是从$\mathbb{R}^{n}$到$\mathbb{R}$的映射,如果$\boldsymbol{y}=g(\boldsymbol{x})$且$z=f(\boldsymbol{y})$。那么
使用向量写法,可等价为
其中$\frac{\partial \boldsymbol{y}}{\partial \boldsymbol{x}}$是$g$的$n \times m$的Jacobian矩阵
梯度下降
梯度下降属于神经网络中优化器的一种,另外还有AdaGrad、RMSProp、Adam等。由于梯度永远指向函数增长最快的方向,那么函数下降最快的方向就是负梯度$-\nabla{f}$。梯度下降算法的思想是构造一个迭代过程,每次都使得损失函数$L$在负梯度的方向步进一点,经过若干次迭代后,函数值最终会逼近极值,这时网络学习收敛
设$\Delta{f}$为每次迭代时函数的变化量,可设置为
其中$\eta$是一个很小的正数,称为学习速率
在每次迭代时$\omega$按照如下规则更新
$b$的更新规则同上。整个迭代过程可以想象为在山谷中下落的小球,小球从山顶会沿着最短路径慢慢滚到谷底,如下图所示
反向传播
反向传播这个术语经常被误认为只是用于神经网络的整个学习算法中,实际上反向传播算法只是用于计算梯度的方法,它可以用来计算任何函数的导数。由于按照梯度的定义直接求解是非常复杂的,反向传播能够使用非常简单的计算步骤来求解梯度
链式法则求复合函数的导数
反向传播的核心在于运用链式法则,以下使用函数$f(x,y,z) = (x+y)*z$来说明整个过程。可将公式拆分为两部分$q=x+y$和$f=qz$
1 | # input value |
对于输入x=-2, y=5, z=-4先进行前向传播,依次向后计算,最后得出函数值为-12,前向传播的方向为从输入到输出(绿色)。反向传播(红色)是从输出开始,根据链式法则递归的向前计算梯度,梯度在链路中回流。最终计算得到梯度[dfdx, dfdy, dfdz]为[-4,-4,3],如图所示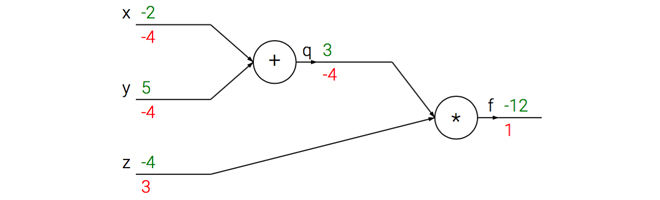
反向传播的直观理解——门单元间梯度的传递
任何可微的函数都可以看做若干个门单元的组合形式,例如加法门、乘法门、除法门、取最大值门等
在整个计算图过程中,每个单元门都会得到一些输入,并计算两个东西:
- 这个门的输出
- 其输出值关于输入值的局部梯度$\nabla{a}$
在反向传播过程中,门单元会获得整个网络输出值在自己的输出值上的梯度$\nabla{b}$,由链式法则可知,将$\nabla{b}$乘以$\nabla{a}$可得到整个网络的输出对于该门的每个输入的梯度
在梯度的回流中,不同的门单元有不同的作用。下图展示了一个反向传播的例子,加法操作将梯度相等地分发给它的输入。取最大操作将梯度路由给更大的输入。乘法门拿取输入激活数据,对它们进行交换,然后乘以梯度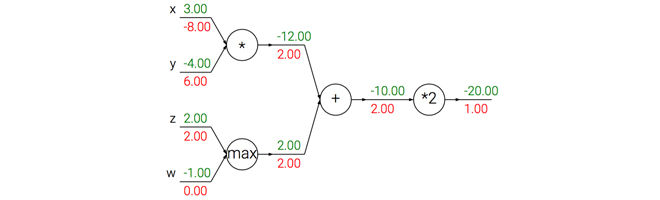
神经网络中的反向传播
在神经网络中,反向传播是对权重和偏置变化影响代价函数$C$过程的理解,最终目的是为了计算偏导数$\frac{\partial C}{\partial \boldsymbol{\omega}}$和$\frac{\partial C}{\partial \boldsymbol{b}}$。定义网络中第$l$层第$j$个神经元上的误差$\delta_{j}^{l}$为
其中$z_{j}^{l}$是第$l$层第$j$个神经元的输出。向量化第$l$层的误差向量为$\boldsymbol{\delta}^{l}$。反向传播提供一种计算每层误差的方法,并将这些误差关联到$\frac{\partial C}{\partial \boldsymbol{\omega}}$和$\frac{\partial C}{\partial \boldsymbol{b}}$上
反向传播的四个基本方程
定义$\boldsymbol{\delta}^{L}$表示输出层误差,对于每个元素,其误差为
其向量形式为公式(BP1)
使用下一层误差$\boldsymbol{\delta}^{l+1}$表示当前层误差$\boldsymbol{\delta}^{l}$
其中$\odot$表示Hadamard乘积。通过公式BP1和(BP2)可以计算任意层的误差$\boldsymbol{\delta}^{l}$,首先使用公式BP1计算输出层误差$\boldsymbol{\delta}^{L}$,然后应用BP2计算$\boldsymbol{\delta}^{L-1}$,然后依次计算完整个网络
代价函数关于网络中任意偏置的改变率为
这表示误差就是偏置的偏导数,向量形式为
代价函数关于权重的改变率为
向量形式为
显示的描述反向传播的步骤
- 输入$\boldsymbol{x}$:为输入层设置对应的激活值$\boldsymbol{a}^{1}$
- 前向传播:对每个层,计算相应的$\boldsymbol{z}^{l}=\boldsymbol{\omega}\boldsymbol{a}^{l-1}$和$\boldsymbol{a^{l}}=\sigma(\boldsymbol{z}^{l})$
- 输出层误差$\boldsymbol{\delta}^{L}$:通过BP1计算
- 反向传播误差:通过BP2计算
- 更新$\boldsymbol{\omega}和\boldsymbol{b}$:通过BP3和BP4计算
实例
以下图网络结构举例来说明反向传播算法是如何工作的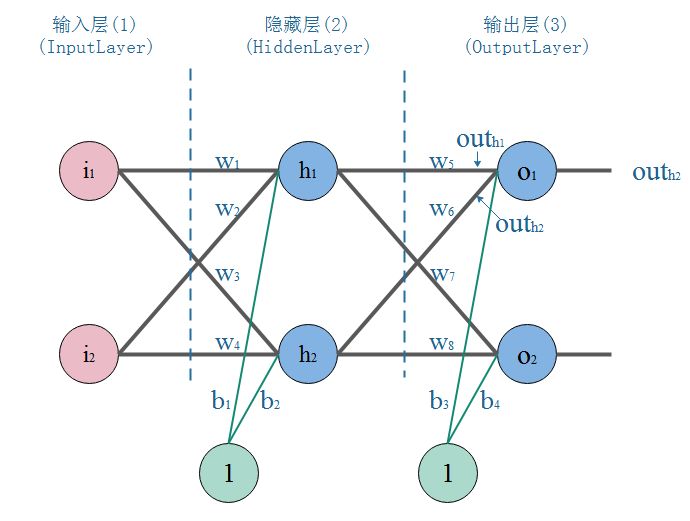
初始化参数
网络中由输入层、1层隐藏层和输出层共3层构成,按照以下参数初始化网络
1 | # 初始化输入输出 |
正向传播
1 | # 计算隐藏层神经元 h1 的输入加权和 |
正向传播结束后的输出结果为[0.7989476413779711, 0.8390480283342561],但是希望的输出是[0.01, 0.99],因此利用反向传播更新权重和偏置,然后重新计算输出
反向传播
代价函数使用
其导数为
根据BP1,输出层神经元的误差$\delta_{j}^{3}$计算方法为
1 | # 计算输出层神经元 o1 的误差 |
根据BP2,隐藏层神经元的误差$\delta_{j}^{2}$计算方法为
在计算时只需要计算与该神经元相关的连接,例如计算隐藏层神经元h1时,只需要计算权重w5和w7,设$\omega_{jk}^{l}$表示从$(l-1)$层第$k$个神经元到第$l$层第$j$个神经元的权重
1 | # 计算隐藏层神经元 h1 的误差 |
根据BP4可计算某个权重的偏导数,例如w5,其偏导数为
1 | # 计算权重 w5 的偏导数 |