经过一个多月工作之余的研究和编码调试,终于将触发词检测的完整方案实现并验证有效,能够在PC端进行独立的实时触发词检测,开源代码见我的开源repo。该project来源于deeplearning.ai的Deep Learning Specialization课程中的”Sequence Models”序列模型,课程中完整介绍了如何搭建一个基于神经网络的触发词检测模型
本文首先对deeplearning.ai的触发词检测课程内容进行介绍,然后对我自己的实现方案进行了介绍说明,最后总结了整个研究过程中的知识点和经验
deeplearning.ai触发词检测
目前很多智能产品上都带有触发词检测功能,例如苹果Siri、百度小度、小米的小爱同学等。触发词检测(Trigger word detect)也叫做关键字检测(keyword detect)或者唤醒词检测(wakeword detect),能够让设备在听到某个特定单词后自动唤醒。该课程介绍了一个触发词检测的通用模型,能够基于该模型训练自己的触发词,并在不同的设备上部署
设计思想
设定一个10秒的检测窗口detect window,将音频内容划分为以下3种类型
background:背景音
activate:激活词,也就是要检测的触发词
negative:负面词,不同于激活词的说话声
10秒的检测窗口中,背景音一直存在,激活词和负面词可以在任意位置出现

将10秒的检测窗口划分为若干个检测单元,未出现触发词的检测单元,将其标签设置为0,出现触发词的检测单元,将其标签设置为1
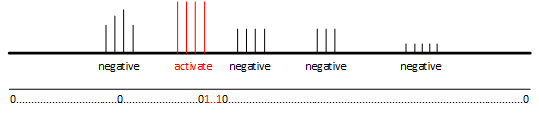
标签1与触发词的出现时间需要有一定的滞后性,因为必须先检测到完整的触发词,才能输出检测到的结果
生成数据集
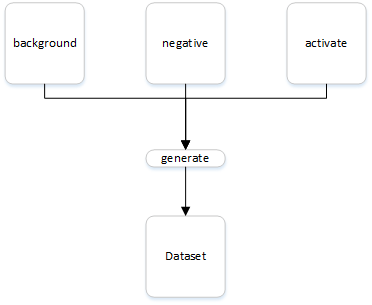
首先需要为触发词检测算法构建一个数据集。理想情况下,最终的模型应该尽可能的在各种场景下都能够进行检测。因此,你需要在不同的背景声音中创建一段录音,例如图书馆、家中、办公室、户外、咖啡厅等等。另外,为了数据和模型有更好的泛化效果,采集的所有样本中,应该将激活次和负面词的出现频率和位置尽可能分布均匀。另外,如果你想要能够识别不同口音,那么需要采集更多样本,包括不同年龄、性别、体重、籍贯等
程序化生成样本
数据集的来源可能是你去收集不同人的录音。如果以10秒的窗口为样本,那么你需要拿着一个录音设备采集多组10秒的音频,以1000个样本数量为例,总的样本时间为10000秒大概是2.7个小时,再加上寻找不同的人和沟通的时间,总的时间成本可能很长
可以使用一个程序化生成样本的方法,将收集的数据分为background、activate和negative三类。background表示在各种环境中采集若干个10秒的背景声音,activate表示采集不同人只说激活词的声音,negative表示不同人只说负面词的声音。采集完成后,将activate和negative样本随机的插入background中,这样能够更加快速的生成更多样本
录音转换为频谱
录音本质上是麦克风记录下气压的微小变化,而这种时域的录音信号,直接用来提取和分析特征,是非常困难的,通过转换到频域,能够更好地提取和利用特征
在Python中,可以用matplotlib.pyplot包的specgram方法实现录音转换为频谱数据
1 | def specgram(filename): |
以上代码,将一个10秒的录音文件转换为频谱数据pxx。这里需要注意一下录音数据和频谱数据的shape
1 | from scipy.io import wavfile |
因为录音使用44100Hz的采样频率,因此1秒产生44100帧音频数据,10秒就是441000帧数据,音频数据是一维的序列。转化为频谱数据后,将10秒划分为了5511个片段,并提取了101个主要频率的窗口
创建一个训练样本
创建训练样本的前提是,已经按照上文的要求,采集了若干数量的背景声、激活词和负面词的录音文件。生成一个训练样本,需要以下4个步骤
随机选择一个背景录音
随机选择若干个激活词音频插入到背景的随机位置
随机选择若干个负面词音频插入到背景的随机位置
对生成的样本进行标记
这里需要注意,插入的过程,是音频数据的叠加操作,而不是追加,例如向一个10秒的背景音频中插入1秒的激活词片段,插入后得到的合成音频仍然是10秒,而不是11秒。在进行多次插入时,为了避免重复插入到相同的位置,需要记录已经插入的片段位置
在进行标记时,将10秒的时长划分为1375,触发词后的50个片段被标记为1,这样做的好处是不需要人为的听取每一个合成音频再手动进行标记,标记过程可以自动进行。1375个片段长度是由模型决定的,后文介绍
模型
使用的模型如图所示
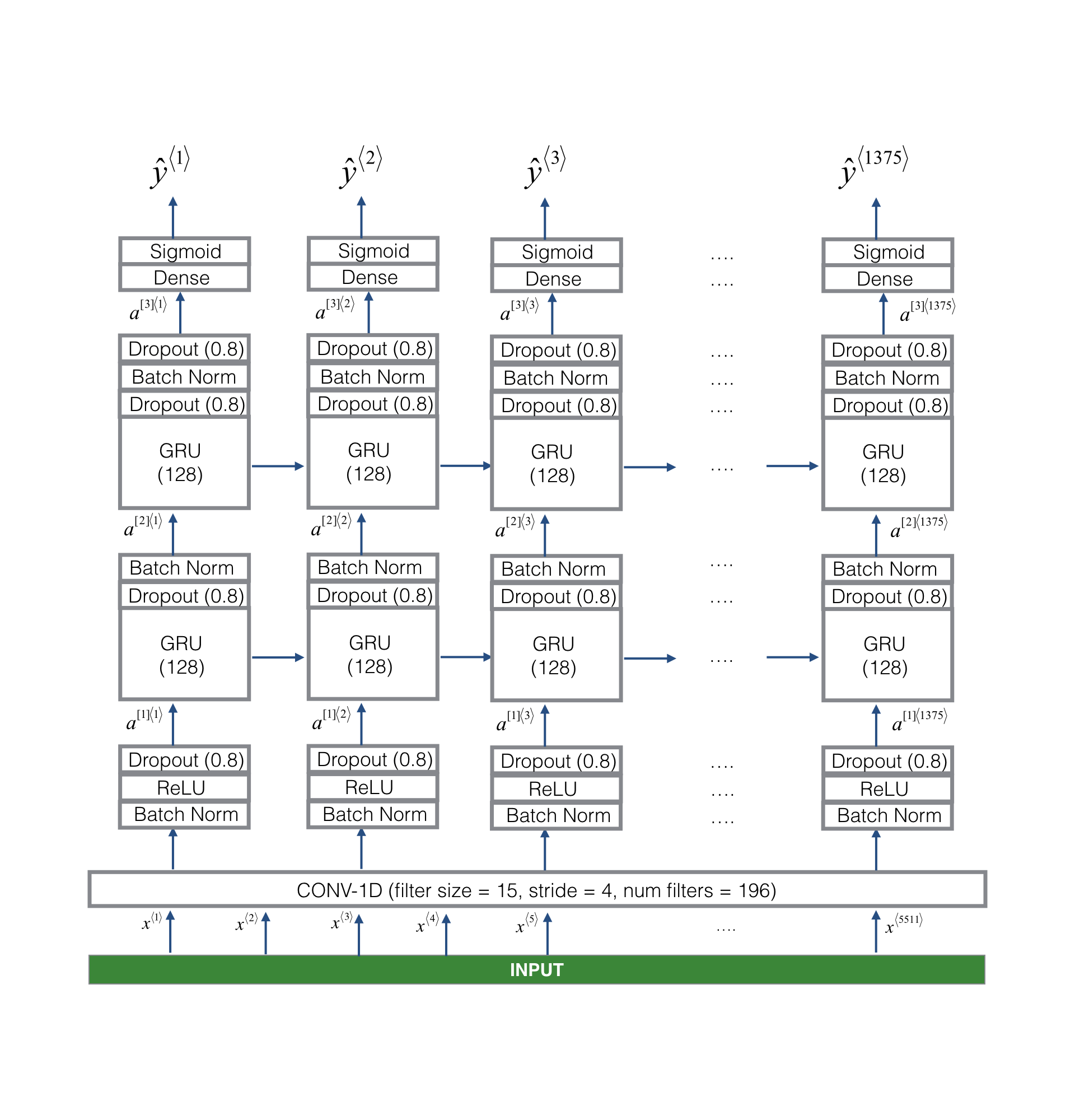
模型的输入是合成音频转化成的频谱数据,shape为(5511,101),输出shape为(1375,)。首先是经过一个一维卷积层,进行简单的特征提取,并减小数据大小到(1375,196),然后数据经过两个GRU层,最后通过Sigmoid函数将输出归一化到0~1
评估和预测
该模型在dev数据集上获得了0.94的精度。在预测时,先将音频数据输入模型,得到模型输出,然后遍历1375个输出数据,如果有连续50个数据大小超过某个阈值(0.6),认为检测到触发词
我的实现
数据集生成
实验环境为Linux,Linux系统为音频处理抽象了一个ALSA框架,包括声卡设备驱动、音频核心层和应用层的一些工具。录音使用”arecord”命令
1 | arecord -xxxx |
另外,还需要两个python音频处理包:pydub和alsaaudio。pydub用于处理音频插入合成,alsaaudio用于实时录音
DataLoader
抽象了DataLoader类来用于加载和生成数据集,代码位于DataLoader.py。设定两个根目录下和数据集相关路径:
orig:表示原始录音数据
gen:表示生成的合成音频和数据集
orig路径下包括background、activate、negative三个文件夹,分别存放背景音、触发词和负面词。gen路径下包括train和dev两部分,分别存放训练集数据和验证集数据
DataLoader主要实现load、info和generate三个方法
1 | class DataLoader(object): |
load主要完成从指定路径加载原始音频文件到内存,默认是从orig路径下加载,也可以从参数指定路径,路径下需要包含background、activate和negative三个子文件夹。info主要是显示loader相关信息,generate方法生成数据集文件,可通过target参数指定是生成训练集还是验证集
load
load方法会遍历远视音频路径下的文件,并按照子文件夹background、activate和negative将音频文件加载到loader的ori_activate、ori_negative和ori_background三个列表中,加载音频文件是调用AudioSegment的from_wav()方法
1 | def load(self, path=None): |
generate
考虑到PC机内存问题,要生成大量数据集文件,使用了batch的方式,generate参数支持批量生成,参数batchs用于控制批次,默认为1,batch_size用于控制单次生成的数量大小
在实现内部,使用yield抽象了一个生成器_generator来生成单个合成音频文件,一个批次的数据通过numpy.save导出为.npy文件
1 | def generate(self, dir=None, target='train', batchs=1, batch_size=100): |
单个生成数据的步骤为
随机抽取一个背景音频
随机抽取几段actives音频,通过
AudioSegment的overlay方法将active插入到background中,这里需要记录已插入的片段起始和结束时间,避免重复或覆盖将插入了activate的位置,在同比例的Y数据中修改标记为1
随机抽取若干negative音频,插入背景中,同样要避免覆盖
将合成后的音频导出为.wav文件
读取.wav合成文件并转换为频谱数据
1 | from DataLoader improt DataLoader |
训练
模型就和deeplearning.ai课程介绍的一致,一个一维卷积层+2个GRU层+一个sigmoid激活函数,网络输入为5511乘101,输出为1375乘1,优化器用Adam,学习速率为0.001,代码如下
1 | def build_model(input_shape=(5511,101), learn_rate=0.001): |
训练使用了GPU加速,在5000个生成数据上进行了训练,没有使用学习速率衰减
1 | def train(modelname, train_index=0, batch_size=10, epochs=30, save=True, lr_reduce=False, use_gpu=True): |
最终的精度达到0.975左右,loss在0.01以下
测试
- 实时预测
总结
利用GRU模型处理时间序列
利用一维卷积预处理
利用GPU加速训练
Linux ALSA框架
train经验
数据问题,数据一定要正确
训练速度问题,先用一个较大的学习速率验证自己数据是否正确,再降低速率进行正式学习