homework3的任务是创建一个用于图像分类的CNN网络,其中可能会用到一些优化技巧。任务包含以下3个级别的要求
Easy:Baseline模型,由作业提供,直接训练可以达到44.862%的精度
Middle:需要使用数据增强技术或者优化网络结构(不可以使用预训练好的网络架构,不能使用额外的数据集),以进行性能的提升,目标精度52.807%
Hard:使用提供的未标记数据获得更好的结果,目标精度82.138%
Dataset
作业使用的数据集是特别处理过的food-11数据集,其中收集了11个食物类别
训练集:280个已标记数据和6786个未标记数据
验证集:60已标记数据
测试集:3347个数据
其中的类别编码为
00:披萨、鸡肉卷、汉堡、土司、面包
01:黄油、芝士、奶酪
02:蛋糕、马卡龙、
03:鸡蛋、煎蛋
04:油炸类食物
05:烤肉
06:意面
07:米饭、炒饭
08:生蚝、扇贝、三文鱼、北极贝
09:各种汤
10:蔬菜水果
Baseline
首先加载各个依赖模块
1 | import torch |
数据准备
数据变换
定义数据转换方式为仅进行resize操作
1 | train_tfm = transforms.Compose([ |
DataLoader
设置batchsize为16,训练集和验证集进行shuffle操作,测试集不进行shuffle操作
1 | batch_size = 16 |
模型定义
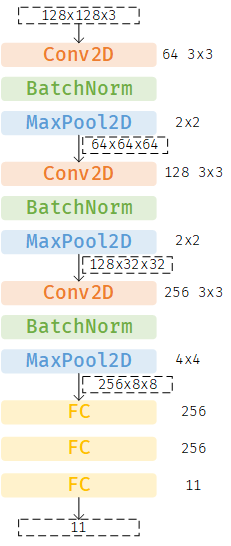
作业给出的基线模型为3个卷积层加3个FC,每个卷积层后跟一个BN、一个ReLU和一个MaxPool
1 | class MyModel(nn.Module): |
模型结构如下图所示
Training
损失函数使用交叉熵,优化器使用Adam,优化器学习率为0.0003,训练批次为80
1 | device = 'cpu' |
经过80批次训练后,验证集精度为0.47173
1 | [ Train | 080/080 ] loss = 0.04817, acc = 0.98478 |
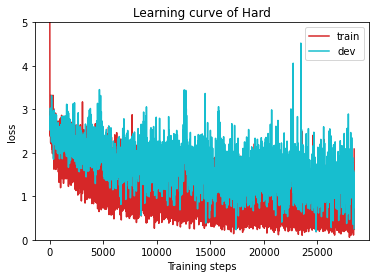
Loss曲线如下图所示,可以看出网络其实并没有收敛,验证集误差还在增大
Middle
optimize1-数据增强
对训练集和验证集使用以下数据增强技术
- 随机水平/垂直翻转
- 随机旋转
- 亮度/对比度/饱和度变换
1 | train_tfm = transforms.Compose([ |
optimize2-使用Resnet18
直接使用pytorch中定义好的Resnet18模型进行训练,但是不加载训练权重参数
1 | model = torchvision.models.resnet18(pretrained=False) |
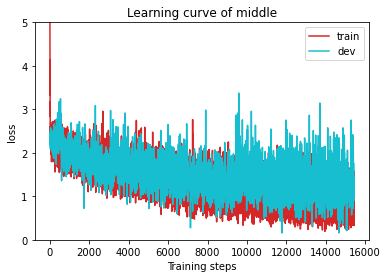
进行80个批次训练后,结果如下
1 | [ Train | 080/080 ] loss = 0.76552, acc = 0.74223 |
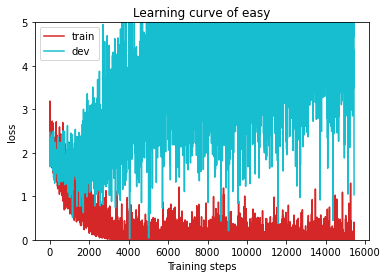
验证集精度达到了59.524%,训练曲线如下
Hard
使用半监督学习技术Semi-Supervised Learning,每次训练时从unlabeled数据中筛选以当前模型输出结果最大置信度超过某个阈值的样本,加入到labeled数据中,构成新的数据集。
模型使用resnet50,训练结果
1 | [ Train | 080/080 ] loss = 0.70109, acc = 0.76370 |