研究Vitis AI好几个月了,终于实现了在VitisAI平台上部署神经网络模型并成功运行的目标,搞清楚了在整个全流程中如何做自定义,这里的自定义主要包括以下几个方面
硬件平台自定义:这里的硬件平台指的不是PCB板级自定义,而是在Xilinx FPGA芯片上的硬件工程自定义。由于不同人不同项目使用的FPGA芯片架构、型号各有不同,为不同的FPGA芯片准备一个DPU可以运行的硬件平台是非常重要的
DPU自定义:模型最终依赖DPU运行,而DPU的编译依赖FPGA芯片资源,不同FPGA芯片资源能力不同,因此需要针对所用的FPGA芯片资源来定制DPU参数
模型自定义:官方仅给出了适用于固定demo板型号的固定数量的预训练模型,而如果所用FPGA平台不是对应demo板的型号,或者想运行自己的模型,需要对模型进行量化压缩编译
本系列将对使用Vitis AI进行神经网络应用加速进行全流程的讲解,阅读本系列,您可以了解到以下内容
进行Vitis AI开发的环境要求是什么,有哪些资源方面的要求?
Vitis AI开发需要下载安装哪些依赖工具,什么才是最为正确和高效的配置方式?
什么是Vitis AI,Vitis AI的软件栈如何使用?
什么是DPU,如何在FPGA上部署DPU,DPU的各个参数是什么含义?
自己做的模型,如何在Vitis AI上做量化和编译,并正确的运行?
如何使用Vitis AI提供的性能分析工具,对所运行的模型进行分析?
Vitis AI 介绍
Vitis AI是Xilinx推出的专用于其硬件平台的AI推理加速开发环境,能够同时适用于边缘计算设备和数据中心加速卡。Vitis AI包含了从底层的IP核、编译器、运行时到C++/Python封装库、性能分析工具、预训练模型、模型量化压缩工具等一系列全栈内容,如下图所示
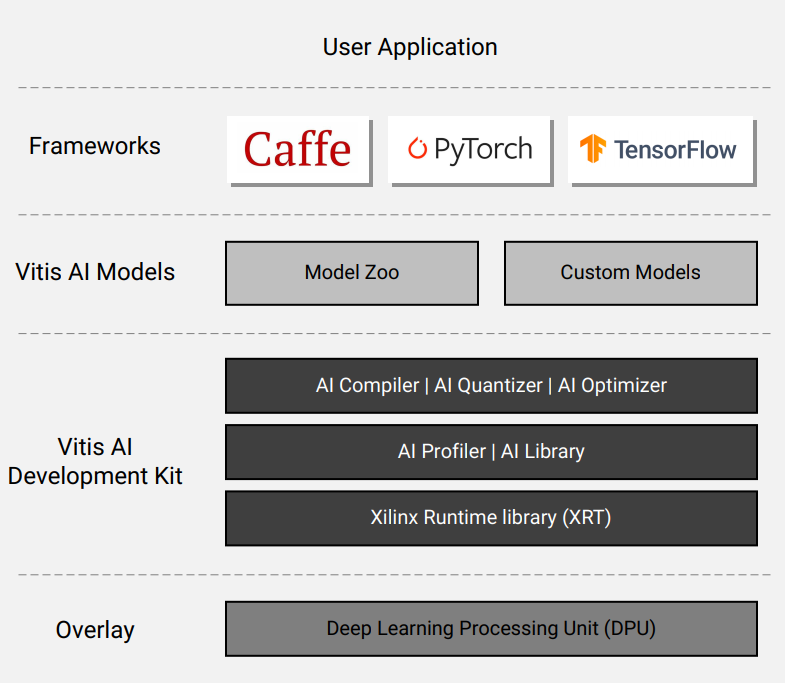
上层是通用的深度学习框架:Caffe、PyTorch和Tensorflow,这一部分并不是VitisAI的内容,模型首先在PC端使用通用的深度学习框架进行训练和评估,Vitis AI使用生成的模型文件
Vitis AI Models Zoo
Models Zoo为开发者提供了一组预优化的深度学习模型,方便开发者进行快速开发。Models Zoo提供了大量的主流深度学习模型,例如用于分类的VGG、Resnet、Inception、Moblienet,用于检测的RCNN、SSD、YOLOv2、YOLOv3,用于图像分割的Enet、Seqnet、FPN、DeeplabV3+,用于姿态估计的Openpose、Coordinates regression等
Optimizer
提供了世界领先的模型压缩技术,可以将模型复杂度降低5至50倍,而精度损失非常小。但是该功能需要购买商业许可
Quantizer
网络模型量化工具,将32位浮点模型转化为INT8。量化后的模型能够减小很多内存和带宽需求,比浮点模型具备更快的访存效率和更高的能效
Compiler
编译器将模型映射为高效的指令集和数据流模型,可以执行复杂的优化,如层融合、指令调度和尽可能多地重用片上内存
Profiler
能够对AI应用进行信息收集和可视化分析,可以进行网络逐层分析以快速发现性能瓶颈
Library
一组高层次统一封装API,支持C++和Python,用于AI模型的高效推理
Runtime
运行时使应用程序能够为云和边缘使用统一的高级运行时API,从而实现云到边缘的无缝和高效部署
DPU
深度学习处理单元(Deep Learning Processor Unit, DPU)是针对深度神经网络优化的可编程引擎,是实现在FPGA中进行AI加速最核心的部件。经过Vitis AI Compiler编译后的模型能够以DPU专用指令集在DPU上运行。Vitis AI对DPU进行了预实现,开发者只需要将其当作一个IP核来使用即可。DPU是可配置的,开发者可自由的在性能与资源占用之间进行权衡,在资源充足的情况下,开发者可以在一个FPGA芯片中部署多个DPU,以实现性能的最大化。不同架构的芯片适用于不同的DPU,Xilinx推出了多个型号的DPU
DPUCZDX8G:用于Zynq UltraScale+ MPSoC
DPUCAHX8H:用于Alveo U50LV/U55C Card
DPUCADF8H:用于Alveo U200/U250 Card
DPUCVDX8G:用于Versal AI Core Series
开发环境介绍
强烈建议使用PetaLinux2021.2版本!!!
首先,非常强烈建议的一点是使用PetaLinux2021.2版本,这是目前PetaLinux最新版本,也是我非常推荐的版本。我曾经使用过2020.1、2020.2、2021.1版本,这几个版本由于历史开发原因,和Vitis AI以及Ubuntu系统适配上做的并不是很好,导致我研究几个月时间里,有超过半数的时间是在反复进行PetaLinux的编译和解决编译中出现的各种各样的错误,而为了解决这些错误去查阅各种PetaLinux和Vitis AI的Issues对于研究Vitis AI来说,并没有什么帮助和收获。因此,我建议使用PetaLinux2021.2版本来进行Linux系统的编译,使用该版本几乎不会出现什么问题,整个编译过程是非常顺畅和迅速的
我的系统配置介绍
我使用的主机CPU为Intel 12700K,运行Windows11操作系统,Vitis AI开发环境是安装和运行在Ubuntu虚拟机上,以下是虚拟机各资源分配介绍
CPU:8核,不知道是由于虚拟机对12代CPU适配问题还是什么原因,如果我把核心数量调整为更多(12或16),在编译PetaLinux过程中必定会出现编译过程停住不动的问题,8核可以正常编译
内存:16G,这个看主机配置情况,分配8G也是可以正常使用的。内存大小主要会影响模型量化时的方式,后文模型量化部分会讲到,不同的量化方式对系统运行内存有不同的要求
磁盘:400G,磁盘大小是非常重要的,主要占用磁盘的部分如下
Vitis统一开发环境,Vivado、Vitis和PetaLinux的安装,需要占用100G+
如果希望PetaLinux编译更快,需要下载离线缓存包进行离线编译,离线缓存包占用100G+
Vitis AI git仓库和进行模型量化编译的Docker镜像,占用100G+
Vivado工程、Vitis工程、PetaLinux工程及Linux镜像编译过程的中间文件,占用几十个G
Ubuntu版本:Ubuntu20.0.4
我使用的FPGA平台是Alinx出的Zynq UltraScale MPSoC XCZU2CGB开发板
需要下载和安装的内容
预先安装好的VMware Workstation和安装Ubuntu20.0.4虚拟机就不介绍了,主要需要下载以下内容
Xilinx Unified Installer 2021.2:Vitis统一安装程序,包括了Vitis和Vivado
PetaLinux 2021.2 安装程序
Ubuntu虚拟机中安装PetaLinux依赖库
PetaLinux离线缓存包(sstate-cache),仅在需要进行离线编译时下载
downloads_2021.2.tar.gz
sstate_aarch64_2021.2.tar.gz
克隆Vitis AI github仓库
在Vitis AI中下载安装Vitis AI Docker
我的虚拟机中路径介绍
1 | |--home |
详细的安装步骤介绍,见本系列其他文章
开发流程介绍
Vitis AI开发流程分为平台流程和应用流程两部分,平台流程一次性构建好后,就不再需要变动,应用流程是需要按功能需求变动的部分
平台流程
平台流程的最终目标是生成可运行于目标平台的Linux镜像,以及DPU运行二进制文件
- Vivado流程:在Vivado中进行Block Design配置,配置好PS侧的时钟、复位、各外设MIO、PCIE、DDR等,并为DPU提供中断、复位和时钟等资源,最终生成硬件描述文件.xsa
- PetaLinux流程:以Vivado流程生成的硬件描述文件为基础,配置Linux内核及rootfs各项功能,配置Yocto的离线编译,最终编译生成内核镜像及根文件系统
- Vitis流程
- 平台工程:以硬件描述文件和PetaLinux编译生成的根文件系统生成Vitis平台工程
- DPU应用工程:以Vits平台工程、PetaLinux编译生成的内核镜像编译生成DPU运行的二进制文件以及合并后的SD卡镜像
应用流程
应用流程主要是模型变动和修改所需做的工作
- 深度学习框架流程:Caffe、PyTorch或Tensorflow上训练生成模型文件
- 模型量化流程:使用Vitis AI的量化工具对模型文件进行量化,生成量化模型
- 模型编译流程:使用Vitis AI的编译工具对量化模型进行编译,生成可部署在DPU上的模型