Tom Mertens、Jan Kautz等人在”Exposure Fusion”这篇paper中提出了一种简单有效的曝光融合方法,通过将一组不同曝光的图像序列进行直接融合得到一副高质量图像,而不需要先将这些图像序列转化为HDR。传统的HDR做法采用多重曝光获得图像序列,需要将其转换为辐照度估计的radiance map,也就是HDR格式的高动态范围图像,然后再进行tone mapping,将高动态范围图像映射为低动态范围的显示设备能够显示的图像。本文对paper的方法进行介绍,并以python代码进行实作
paper介绍
结果展示
论文中以威尼斯水城的3张不同曝光图像序列作为输入,如下图所示

处理后的图像如下

输入序列中的3幅图像,第1幅曝光时间最短,天空和水面的纹理细节得以保留,而建筑物和船只的很多细节都丢失了。第2幅图像曝光时间适中,天空和水面仍有部分细节,建筑物细节和船只的细节增多。第3幅图曝光时间最长,天空过曝,水面有部分细节,建筑物和船只的细节最为充分。可以看出,经过融合之后的图像结合了3副图像各自的优势,每幅图像不同区域的细节都得以保留,而信息丢失的部分已经尽可能丢弃掉了,效果非常好
该方法的优势
pipeline得以简化:通常的HDR做法需要从多张曝光图像序列中合成高动态范围图像,需要恢复相机特定的响应曲线。另外,由于大多数显示设备动态范围有限,不能直接显示HDR图像,需要通过tone mapping压缩动态范围以适应显示设备的动态范围。而本方法则简单很多
不需要担心相机的校准问题,也不需要记录每张照片的曝光时间(响应曲线的校准需要知道每张照片的曝光时间)
曝光序列中可以允许过度曝光的部分,传统HDR方法由于要恢复响应曲线,存在过曝的图像不能使用
Exposure Fusion
曝光融合通过只保留多次曝光图像序列中的“最佳”部分来计算所需的图像。什么是“最佳”是由一组质量度量指标来确定的,通过这些指标来对图像进行衡量并分配权重。最后合成的图像是利用拉普拉斯金字塔进行融合的。该paper中假定所有图像序列都是对齐的
质量衡量标准
由于曝光不足和过度曝光,序列中会包含很多平坦和无色的区域。这样的区域权重应该尽可能少,而颜色鲜艳和细节丰富的区域应该得到充分保留
paper中提出了以下3种指标
对比度(Contrast):将拉普拉斯滤波器应用到每张图像,并取滤波器响应的绝对值,将其作为对比度的简单指标C。对比度越高表明纹理和边缘越多,这部分像素的权重应该更高
饱和度(Saturation):在每个像素位置上进行饱和度测量S,计算方式为R、G、B三通道的标准差
良好曝光(Well-exposedness):希望每个像素位置良好曝光(既不要曝光不足也不要曝光过度),即认为像素值接近中间为最好,例如归一化的像素值为0~1,那么0.5为最好,使用一个均值为0.5的高斯曲线来衡量像素值离0.5的距离,越近代表越好,得到指标E
每个像素不同度量信息相乘,得到每张图像的权重,使用一个幂函数来控制每个指标的影响程度
\begin{equation}
W{ij,k} = (C{IJ,K})^{\omega {C}} \times (S{ij,k})^{\omega{S}} \times (E{ij,k})^{\omega_{E}}
\end{equation}
其中$k$表示曝光序列中的第$k$次曝光,$i,j$表示像素位置,$W_{ij,k}$表示第$k$次曝光图像的像素$i,j$处的权重
融合
计算每个像素的加权平均值来融合N个图像。需要对权重进行正则化
\begin{equation}
\hat(W{ij,k}) = [\sum{\acute{k}=1}^{N}W{ij,\acute{k}}]^{-1}W{ij,k}
\end{equation}
paper中提到,如果使用简单的权重和图像进行加权平均,得到的融合图像并不让人满意,会在边界产生光晕和接缝问题。最终paper中选择拉普拉斯金字塔来进行多个图像的融合
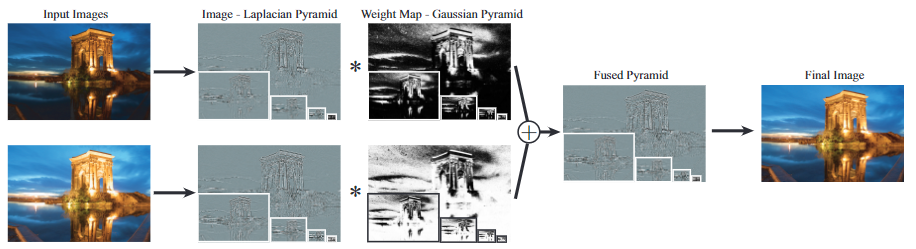
普拉斯金字塔的详细介绍见另一篇文章DIP-图像金字塔
python实作
首先导入依赖库
1 | import cv2 |
读入图像并显示
1 | image_list = [ |

定义对比度、饱和度和良好曝光的权重函数
1 | def contrast_weights(im): |
对图像序列进行权重计算并显示权重图片
1 | for i, im in enumerate(images): |
图像1的原图、对比度图、饱和度图以及曝光良好图

图像2的原图、对比度图、饱和度图以及曝光良好图

图像3的原图、对比度图、饱和度图以及曝光良好图

图像4的原图、对比度图、饱和度图以及曝光良好图

可以看到对比度图能够提取图像明显的边缘细节,对比度图能够踢球色彩艳丽的区域,曝光良好图能够提取亮度适中的区域
定义曝光融合函数
1 | def exposure_fusion(images, measure_weights=(1.0, 1.0, 1.0), best_expo=0.5, sigma=0.2, |
融合结果如下

Reference
Mertens, Tom, Jan Kautz, and Frank Van Reeth. “Exposure fusion.” Computer Graphics and Applications, 2007. PG’07. 15th Pacific Conference on. IEEE, 2007.