本文源自ARM CMSIS-NN项目的一篇论文”CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs”。CMSIS-NN是一种高效的内核,用于将最大化性能和最小化内存占用的神经网络应用于Arm Cortex-M处理器上。基于CMSIS-NN核的神经网络在推理运行时间上提高4.6倍,在能效上提高4.9倍
随着物联网的发展,各种边缘设备的规模迅速发展,各种边缘设备收集的数据需要经由无线网络传送到云端处理。随着节点数量的增加,对网络带宽造成了很大的负担,并增加了延迟,另一方面是数据的安全问题。一个好的解决方案是边缘计算
另一方面,深度神经网络在很多复杂任务中的表现已经超过人类,例如图像分类、语音识别、自然语言处理等。但是由于计算复杂度和资源要求较高,NN的执行主要局限于高性能服务器或专用硬件加速的云计算服务,这增加了网络负担。如果能在数据收集的边缘设备上部署一些小型的神经网络进行简单轻量化任务,这将减少整个网络的延迟和能源消耗
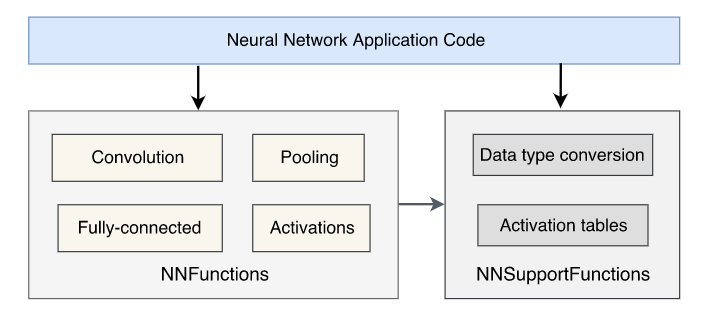
CMSIS-NN的神经网络内核结构如图,内核代码包括两部分:NNFunctions和NNSupportFunctions。NNFunctions包括一些神经网络层函数,如卷积、深度可分离卷积、全连接、池化和激活等,这些函数可被应用程序代码调用以实现神经网络推理。NNSupportFunctions包括一些实用的计算函数,如数据转换、一些查找表
定点量化
神经网络模型使用32位浮点数据进行训练,然而在推理过程中并不需要这么高的精度。研究表明,即使在低精读定点表示下,神经网络也能很好的工作。定点量化有助于避免昂贵的浮点计算,并减少存储权重和激活函数的内存占用,这对于资源受限的平台至关重要。CMSIS-NN同时支持8位和16位的定点
CMSIS-NN中使用q7_t和q15_t来表示int8和int16类型。量化方式使用的是”Power of 2”,即将数据表示为$A \times 2^{n}$的形式,其中$A$为整数值,$n$为缩放因子,内核在进行运算时使用移位来量化和反量化。这种量化方式的好处是不需要额外的FPU来进行浮点数据运算,很多微控制器没有FPU
优化的内核
Arm Cortex-M处理器支持SIMD指令,特别是对神经网络计算非常有效的16位乘积指令
Support Functions
大多数NNFunctions使用16位的乘积指令,因此需要将q7_t转为q15_t。CMSIS提供了一个实用的函数arm_q7_to_q15。数据转换分两步完成,第一步是通过使用符号扩展指令__SXTB16将8位数据扩展为16位,第二步是重新排列数据,使输出数据与输入数据顺序相同
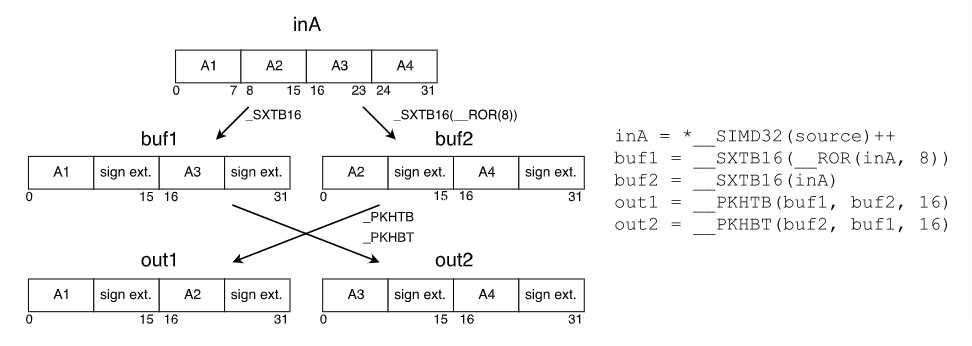
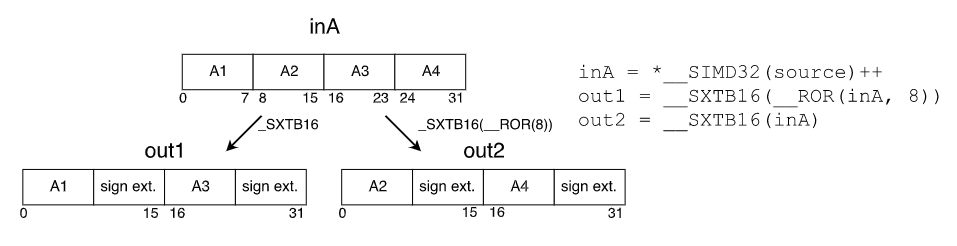
因为在NN计算过程中,需要调用很多次数据转换,因此它的性能至关重要。如果两个操作数遵循相同的的顺序,则可以省略第二步的重新排序。为了更好的利用这一点,创建了另一个版本的数据转换,不需要重新排序
矩阵乘法
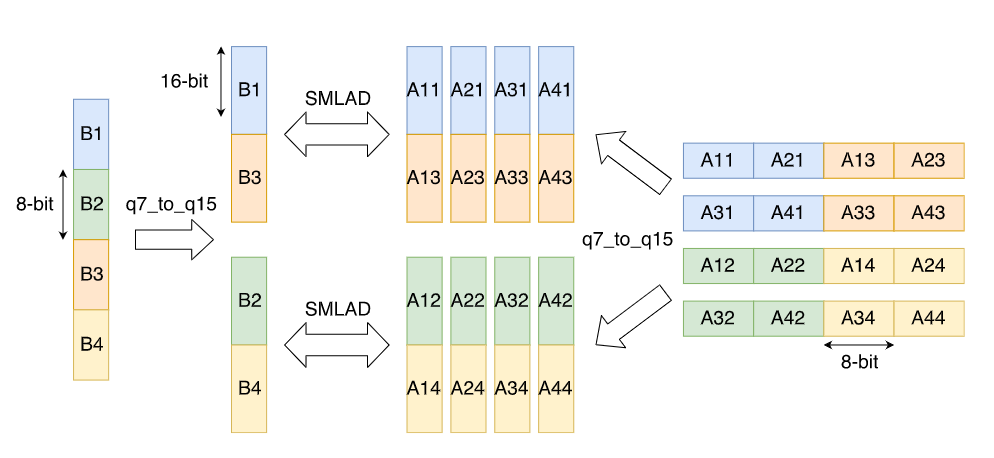
矩阵乘法是神经网络中最重要的计算核,CMSIS中使用2x2的核来实现。乘积结果是32位数据,乘积使用__SMLAD
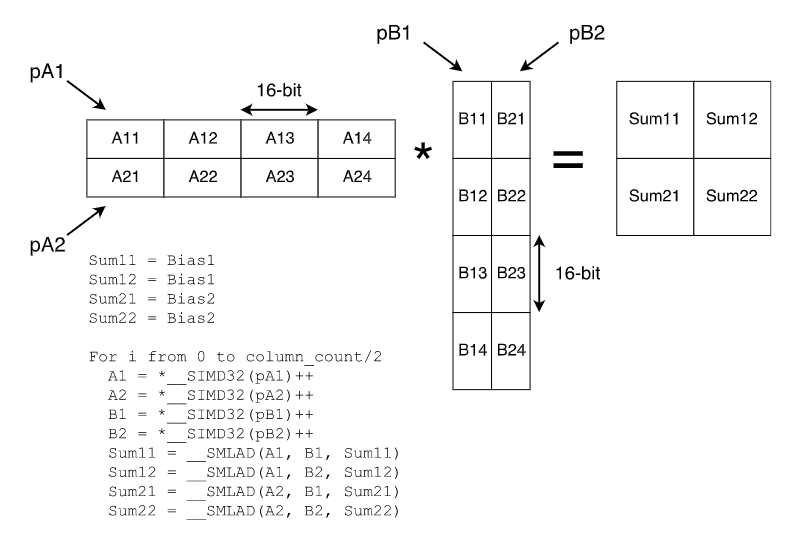
正常的操作下,Sum11是由A的第一行与B的第一列对应元素乘积的和构成,每次取一个元素,则需要循环4次
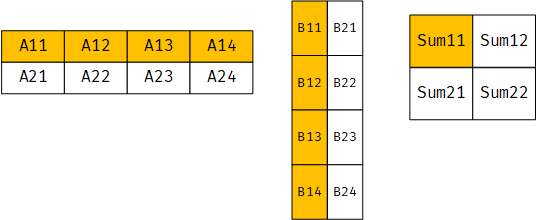
__SIMD32指令一次取32位数据,由于数据是q15_t的,因此一次可以读入2个数据,只需循环两次即可完成
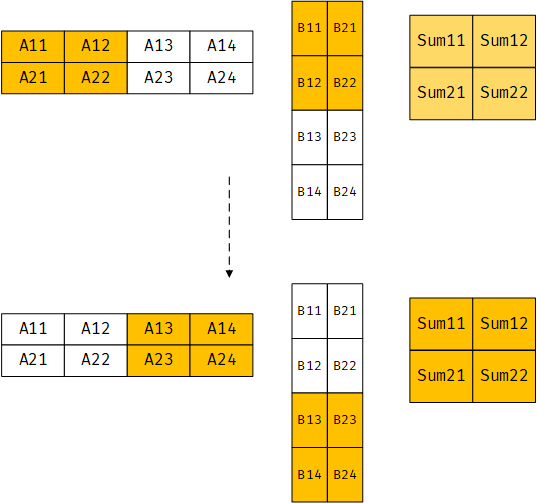
上文中提到q7_t扩展到q15_t去掉重新排列的问题,在矩阵乘法中,可以不用进行重排来提高性能。但是当元素数量不是4倍数时,数据对齐会比较棘手
如下图,q7_t扩展到q15_t时,A和B的数据元素位置都交错了,但是由于相乘时元素的对应关系没有改变,因此结果不变
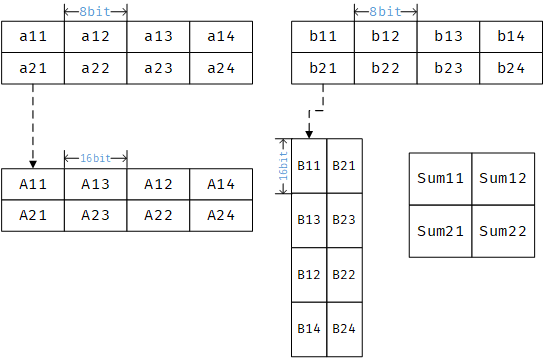
另一种场景是q7_t的权重和q15_t的激活函数。这种情况下,权重可以通过交换每32位的第二和第三字节进行预处理,即将[1,2,3,4]转换为[1,3,2,4],经过预处理后,不需要重新排序,扩展后的权重数据顺序会回到[1,2,3,4]
全连接层的向量与矩阵乘法也可以利用1x2的核来提高性能
由于权重一直保持不变,并在推断期间重复使用,可以重新排序权重矩阵,以便行数据交错,并且只需要一个指针访问就可以读取。这种权重调整如图所示
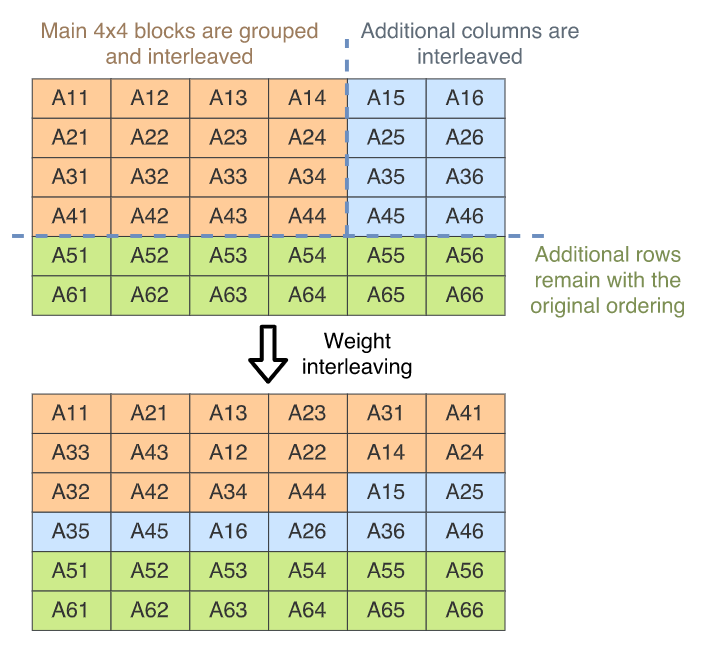
矩阵向量相乘时,使用相同的q7_t扩展到q15_t函数,不需要重新排列,这样可以使用可用的寄存器来容纳1x4的内核
卷积
通常,一个基于CPU的卷积实现被分解位输入重新排序和展开(im2col)以及矩阵乘法。im2col是将类似图像的输入转换为表示每个卷积滤波器所需数据的列的过程
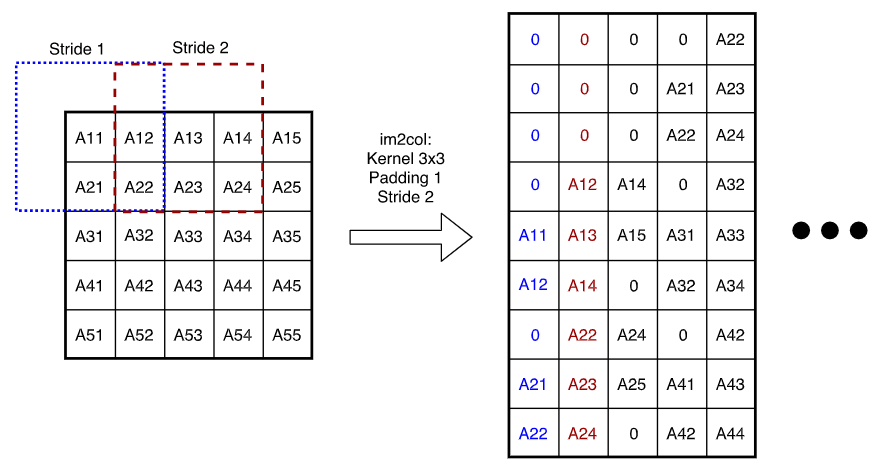
im2col的主要问题是内存占用很高,im2col矩阵中有很多重复项。为了解决内存占用问题,同时保留im2col带来的性能优势,为卷积内核实现了部分im2col。内核只会扩展为有限的列,足以从矩阵乘法内核获得最大性能提升,同时保持最小内核开销
数据格式也会影响卷积性能。当batchsize为1时,卷积操作是对3D数据的二维卷积,延两个方向移动
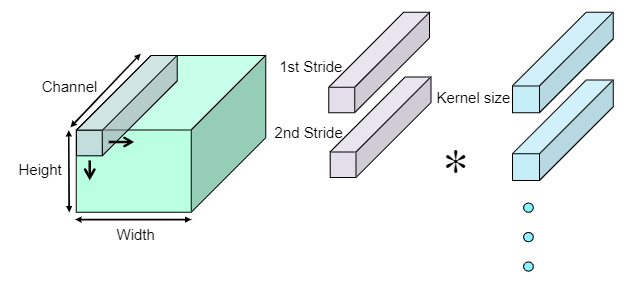
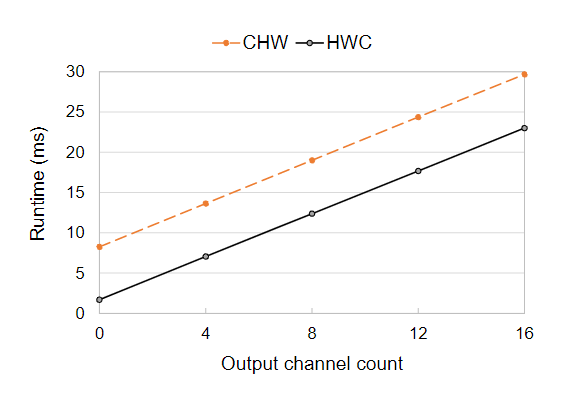
最常见的两种图像数据格式是CHW和HWC。在HWC格式中,沿通道的数据以步长1存储,沿宽度的数据以通道计数的步长存储,沿高度的数据以(通道计数x图像宽度)步长存储。HWC格式的数据可以实现高效的数据移动,每个像素是连续存储的,可以通过SIMD指令高效的复制。在Arm Cortex-M7上将CHW和HWC进行了比较,HWC输入固定为16x16x16,当输出通道为0时,意味着只执行im2col操作,不执行矩阵乘法。与CHW格式相比,相同矩阵乘法,HWC有更少的运行时间
Pooling
与卷积类似,池化是一个基于窗口的操作,具有给定的内核大小,步长和填充。与卷积不同,池化通常在同一通道内操作,并独立于其他通道的数据。一个有效的池化替代方案是将池化操作分为x池化和y池化。这样,x方向上的池化操作(最大、平均)可以在y方向上重复使用,从而减少了操作总数,称这种方法为x-y池化。x-y池化的一个潜在问题是数据安排,因为需要额外的内存来存储中间结果。为了消除额外内存的要求,内核在原位进行池化,这样池化对输入数据进行了破坏

激活函数
ReLU
CMSIS中使用类似SWAR的概念来实现ReLU。关键是识别q7_t的符号位,如果数字为负数,则使其为0。实现方式如下图
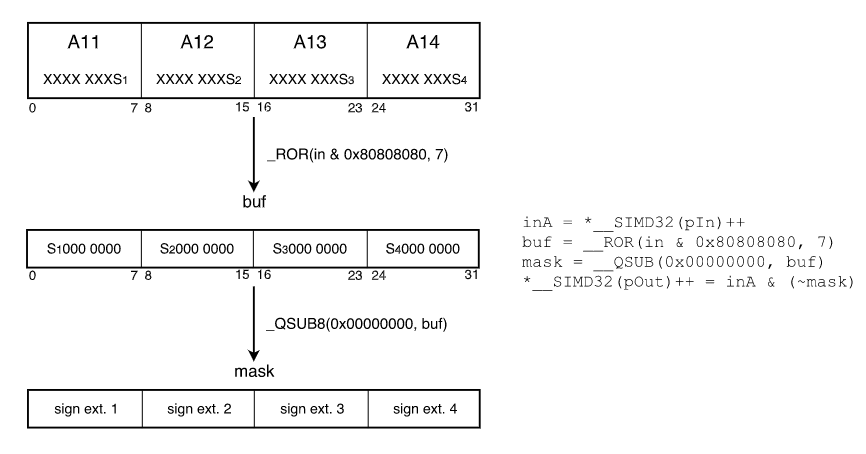
将符号位提取出来构成一个字节,通过使用字节级减法指令__QSUB8将0与符号位提取生成的字节数相减,得到一个掩码,如果是负数,则提取的字节为0x01,0减去0x01为0xFF,那么原始数据与0xFF的非得到0,如果是整数,0减0依然是0,原始数据与0x00的非还是原始数据
Sigmoid and Tanh
sigmoid和tanh需要使用专用的数学函数,这种计算在Cortex-M架构的CPU上计算程本很高,因此使用固定输入和固定输出的查找表来实现。有两种方式实现的查找表,第一种是对所有范围使用一个统一的表,输入粒度固定,输入的MSB用于识别查找表中的条目,LSB可以用于线性插值
另一种选择是实现两个独立的表,以覆盖函数的不同区域,这样精度更高,因为sigmoid和tanh都是高度非线性的。对于0附近的输入区域,应该有一个细粒度的表,对于绝对值较大的区域,有另一个粗粒度的表
确定sigmoid和tanh函数表的范围是很重要的,CMSIS中使用了[-8,8],因为sigmoid(8)=0.9997,tanh(8)=0.9999
实验结果
在CIFAR-10数据集上训练的CNN测试了CMSIS-NN内核,该数据集由6万张32x32的彩色图像组成,分为10个类别。网络结构如下表,3个卷积层和一个全连接层。所有权重和激活函数都量化为q7_t
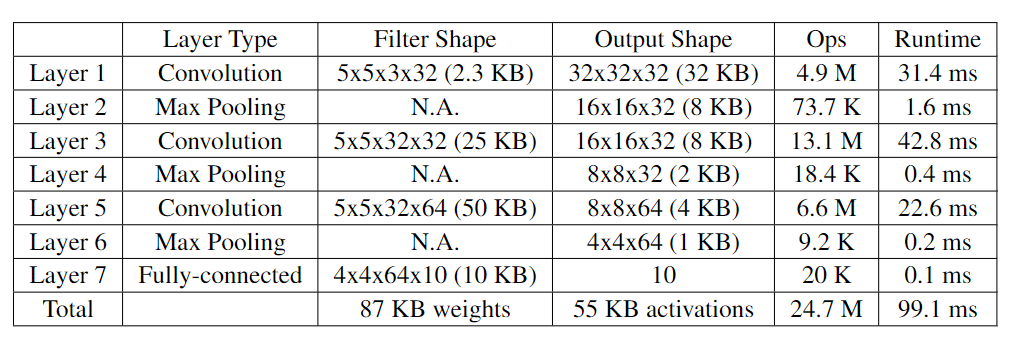
整个图像分类每张约运行99.1ms,帧频约为10fps。运行该网络时,CPU计算吞吐量大约为每秒249MOps。在CIFAR-10测试集上,预量化网络准确率达到80.3%,在Arm Cortex-M7上运行的8位量化网络达到79.9%。使用CMSIS-NN内核最大内存占用为133KB,其中使用部分im2col实现卷积以节省内存。如果不使用部分im2col,内存开销将到达332KB
为了量化CMSIS-NN内核相对于现有方案的优势,使用了一维卷积函数实现了一个基线版本。下表总结了基线版本与CMSIS-NN的结果比较,CMSIS-NN在运行时间上比基线版本提高了2.6倍,吞吐量上提高了5.4倍

Reference
arxiv - CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs