本文对DPU的一些配置选项进行介绍。主要参考文档为pg338,”DPUCZDX8G for Zynq UltraScale+MPSoCs Product Guide”
DPU配置文件
对DPU配置的描述在Vitis工程中,以本系列使用的Vitis工程路径为例,在dpu_trd_system/dpu_trd_kernels/src/prj/Vitis/dpu_conf.vh文件中
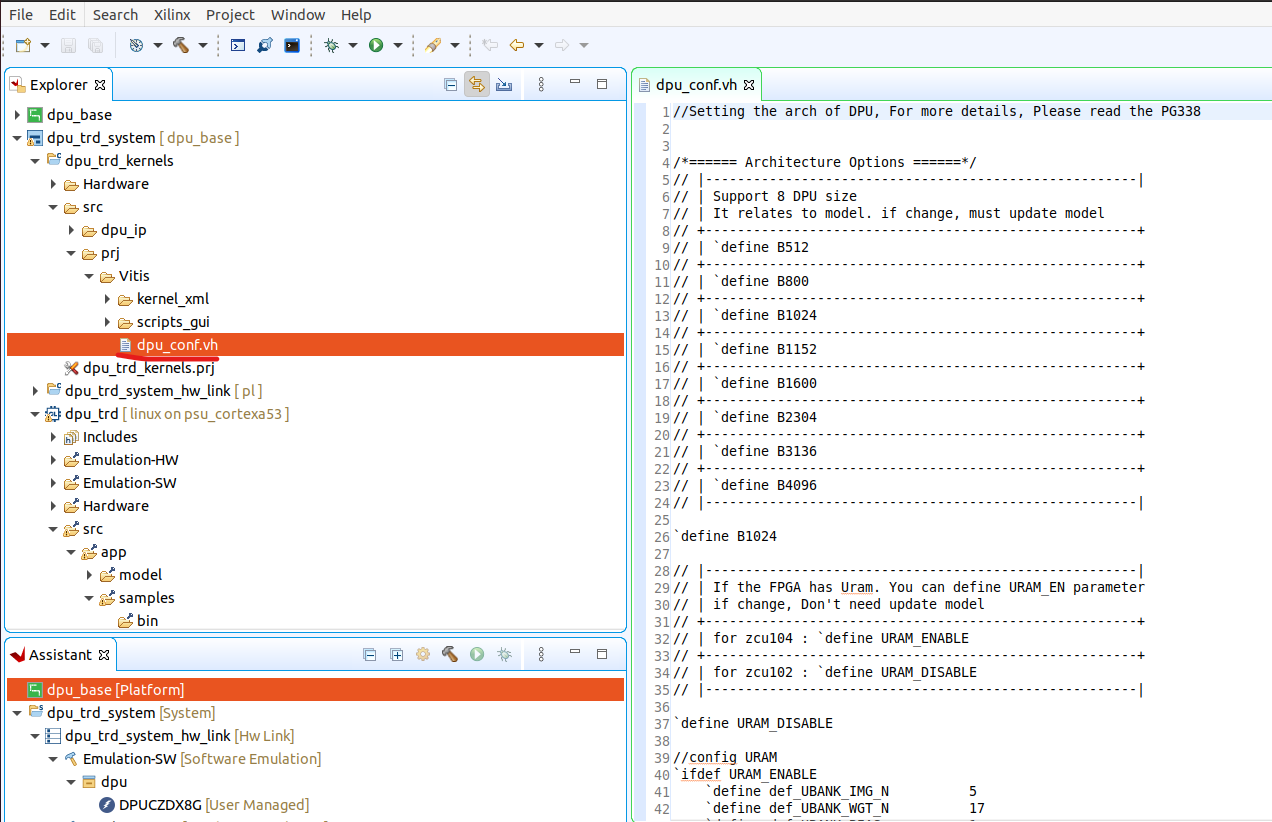
该文件中对DPU的配置项主要有以下6个部分
Architecture Options
URAM Enable/Disable
DRAM Enable/Disable
RAM Usage Configuration
Channel Augmentation Configuration
DepthWiseConv Configuration
Pool Average Configuration
Multiplication Feature Maps
RELU Type Configuration
DSP48 Usage Configuration
Power Configuration
DEVICE Configuration
Architecture Options
DPU可以被配置为多种多样的卷积架构,这些架构与卷积单元的并行度有关。DPUCZDX8G的可选架构有:B512、B800、B1024、B1152、B1600、B2304、B3136和B4096。不同的架构对逻辑资源的要求不同,更大的架构能够获得更高性能但是代价是占用更多资源
以下是不同架构在LUT、Register、Block RAM、DSP方面的资源占用情况
| Architecture | LUT | Register | Block RAM | DSP |
|---|---|---|---|---|
| B512 | 27893 | 35435 | 73.5 | 78 |
| B800 | 30468 | 42773 | 91.5 | 117 |
| B1024 | 34471 | 50763 | 105.5 | 154 |
| B1152 | 33238 | 49040 | 123 | 164 |
| B1600 | 38716 | 63033 | 127.5 | 232 |
| B2304 | 42842 | 73326 | 167 | 326 |
| B3136 | 47667 | 85778 | 210 | 436 |
| B4096 | 53540 | 105008 | 257 | 562 |
在DPUCZDX8G的卷积操作有3个维度的并行度:像素级并行(Pixel Parallelism,PP)、输入通道并行(Input Channel Parallelism,ICP)和输出通道并行(Output Channel Parallelism, OCP),以下是不同架构的并行度情况
| Architecture | PP | ICP | OCP | Peak Ops |
|---|---|---|---|---|
| B512 | 4 | 8 | 8 | 512 |
| B800 | 4 | 10 | 10 | 800 |
| B1024 | 8 | 8 | 8 | 1024 |
| B1152 | 4 | 12 | 12 | 1152 |
| B1600 | 8 | 10 | 10 | 1600 |
| B2304 | 8 | 12 | 12 | 2304 |
| B3136 | 8 | 14 | 14 | 3136 |
| B4096 | 8 | 16 | 16 | 4096 |
可以看到,架构的命名方式是以每个时钟周期的操作量而定,因为卷积操作是一个乘法跟一个加法,因此单周期操作数为PP*ICP*OCP*2
dpu_config.vh文件中,可以通过如下部分设置所选用的架构
1 | /*====== Architecture Options ======*/ |
这里选用的是B1024,如果选用其他架构,直接修改B1024替换为所选用架构的名称即可
RAM Usage
权重、偏置和运算过程的一些立即数据是存储在片上内存中的,片上内存包括Block RAM和UltraRAM,不同架构的RAM占用情况不同,高内存占用(High Usage)意味着DPU能够更加灵活的处理中间数据,更高的性能
dpu_config.vh中与RAM相关的配置有URAM、DRAM和RAM
以下配置用于开启或关闭URAM的使用,请注意你所使用的FPGA芯片是否有支持URAM
1 | // |------------------------------------------------------| |
以下配置用于开启或关闭DRAM,请注意你所使用的FPGA芯片是否有支持DRAM
1 | // |------------------------------------------------------| |
以下配置用于选择Block RAM的使用是高占用还是低占用
1 | // |------------------------------------------------------| |
Channel Augmentation
通道增强可以用于提升DPU效率,不同架构DPU输入通道最大可以到8的并行度,而一般的卷积运算尤其是图像领域,输入通道通常为3,这样没有充分利用所有输入通道的并行性,而启用通道增强,可以最大程度利用输入通道的并行性
以下是对通道增强的配置,只能选择开启或关闭
1 | // |------------------------------------------------------| |
DepthwiseConv
在标准的卷积操作中,每个输入通道对应一个kernel,将所有通道的运算结果结合得到最终卷积结果。而在深度可分离卷积中,运算分为两个步骤:深度卷积和点卷积。深度卷积是指对每个特征图进行单独计算。点卷积是进行1x1的标准卷积。深度可分卷积的并行度只有标准卷积的一半,可以大大提升卷积效率
以下是深度可分卷积的配置
1 | // |------------------------------------------------------| |
ElementWise Multiply
元素点积计算两个特征图的Hadamard乘积
1 | // |------------------------------------------------------| |
AveragePool
该选项决定DPU是否支持平均池化,大小可选2x2、3x3到8x8
1 | // |------------------------------------------------------| |
ReLU Type
ReLU类型决定DPU可用哪种ReLU函数,默认支持ReLU和ReLU6
以下是ReLU的配置,最多只能选择ReLU+LeakyReLU+ReLU6
1 | // +------------------------------------------------------+ |
Softmax
该选项可以在硬件实现Softmax操作,硬件实现的Softmax是一个独立的加速器,能够支持INT8输入和浮点输出。硬件实现的Softmax比MPSoC上软件实现的Softmax快160倍。硬件实现的Softmax最大只支持1023个分类的任务,如果类别数超过1023则只能使用软件实现
硬件Softmax并非在dpu_config.vh中配置,而是在vitis的UI界面中添加