巧妙的使用共享内存Shared memory,能够减少线程对全局内存Global memory的访问,提升CUDA程序在访存方面的性能。本文以矩阵乘法为例,通过对比不使用共享内存的普通矩阵乘法实现和使用共享内存的矩阵乘法优化版本,展示共享内存对程序性能的提升,并分析使用共享内存的条件和注意点
普通矩阵乘法
矩阵乘法的基本原理如下图所示
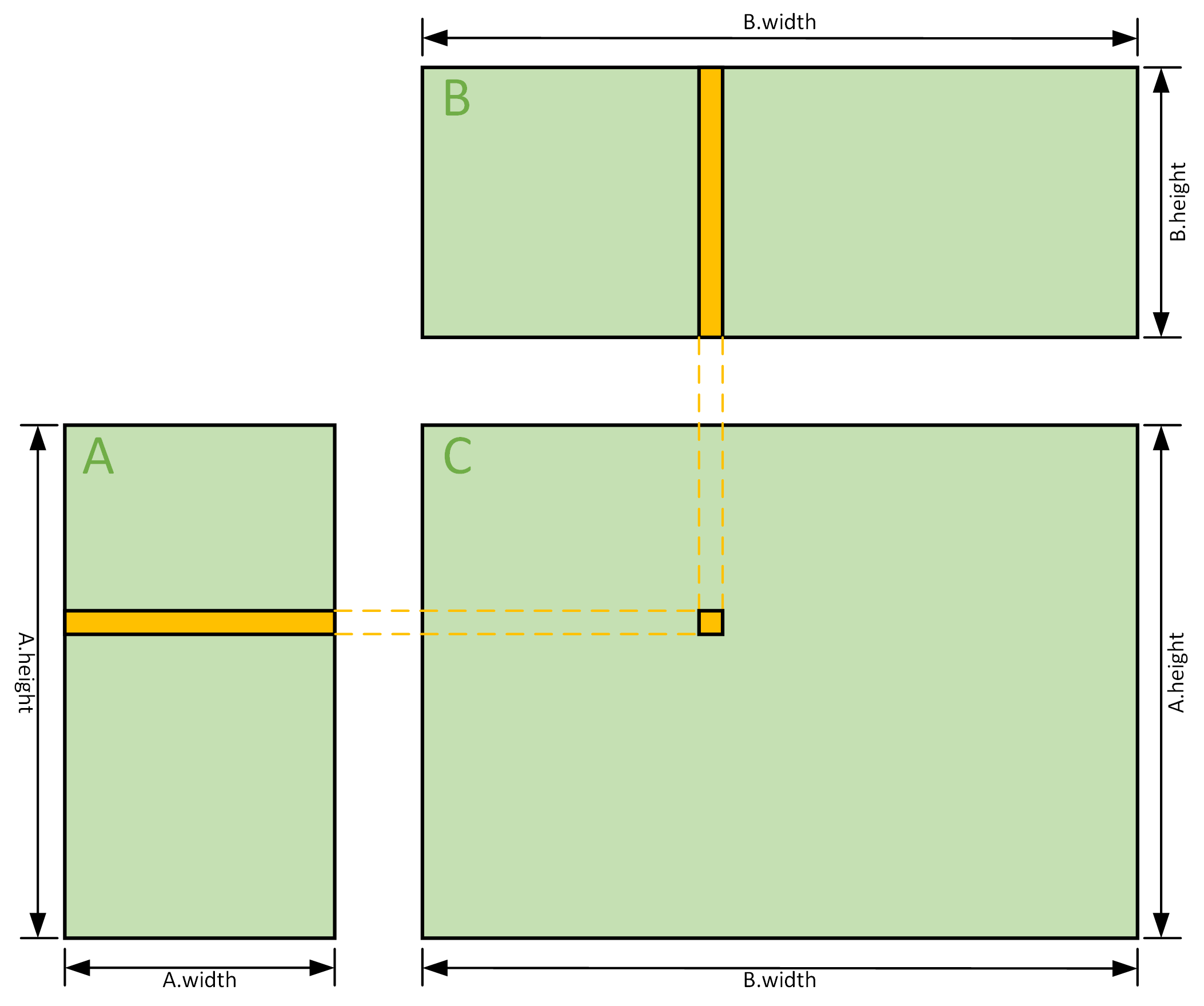
矩阵A与矩阵B相乘,得到矩阵C,相乘的一个重要条件是矩阵A的列数或者宽度与矩阵B的行数或者高度要相等,相乘得到的矩阵C的列数(宽度)与矩阵B的列数(宽度)相等,行数(高度)与矩阵A的行数(高度)相等,假设A为2x3的矩阵,B为3x4的矩阵,A和B相乘结果是C为2x4,注意这里的表述是行在前列在后。乘法中单个元素的对应关系是,C中的每个元素是A中对应行与B中对应列的逐元素相乘的累加和,如图中黄色部分,整个乘法过程可以抽象成一个两层循环,外层循环是C中每个元素位置的循环,内层循环是A的行与B的列的逐元素循环
普通矩阵乘法的示例代码如下
1 |
|
程序中为每个block分配了16x16的二维线程数,block的大小由数据大小决定,每个线程计算C中的一个元素,通过线程的二维ID来确定当前线程计算C中的哪个元素
使用共享内存优化矩阵乘法
在普通矩阵乘法中,每个线程负责计算C中的一个元素,每个元素都会读取A中的一行和B中的一列。例如在计算C[2][1]时,线程1要读取一次A的第2行和B的第1列,在计算C[2][2]时,线程2要读取一次A的第2行和B的第2列,可以看到两个线程各进行了一次对A第二行的读取操作,由于从全局内存中读取数据是非常缓慢的,这种重复的读取如果可以被避免的话,能够有效提升程序性能。如下图所示,在优化的程序中,将最终要计算的结果矩阵C拆分成一个一个大小为 BLOCK_SIZE*BLOCK_SIZE的子矩阵$C{sub}$,每个线程块负责计算一个子矩阵$C{sub}$,而每个线程负责计算子矩阵中的每个元素。对A、B的读取也是以块为单位的,每次将读取的数据放入SharedMemory中,这样在计算完一个子矩阵$C_{sub}$时,对A的行读取、B的列读取能够从SharedMemory中获得,而不是每次都从全局内存中获取
1 |
|
Performance
| 显卡 | KernelVersion | KernelLaunchTime(us) |
|---|---|---|
| GTX 730(sm_35) | V1 | 2849372.820 |
| GTX 730(sm_35) | v2 | 2154518.019 |